Pope Tech release notes for October 2020.
Oct 29, 2020
Errors by Group Dashboard widget updates
The chart has been updated to be a horizontal bar chart with each category in its own bar underneath the one above instead of stacking in one bar. This change was made to make it more clear what the totals are for each result.
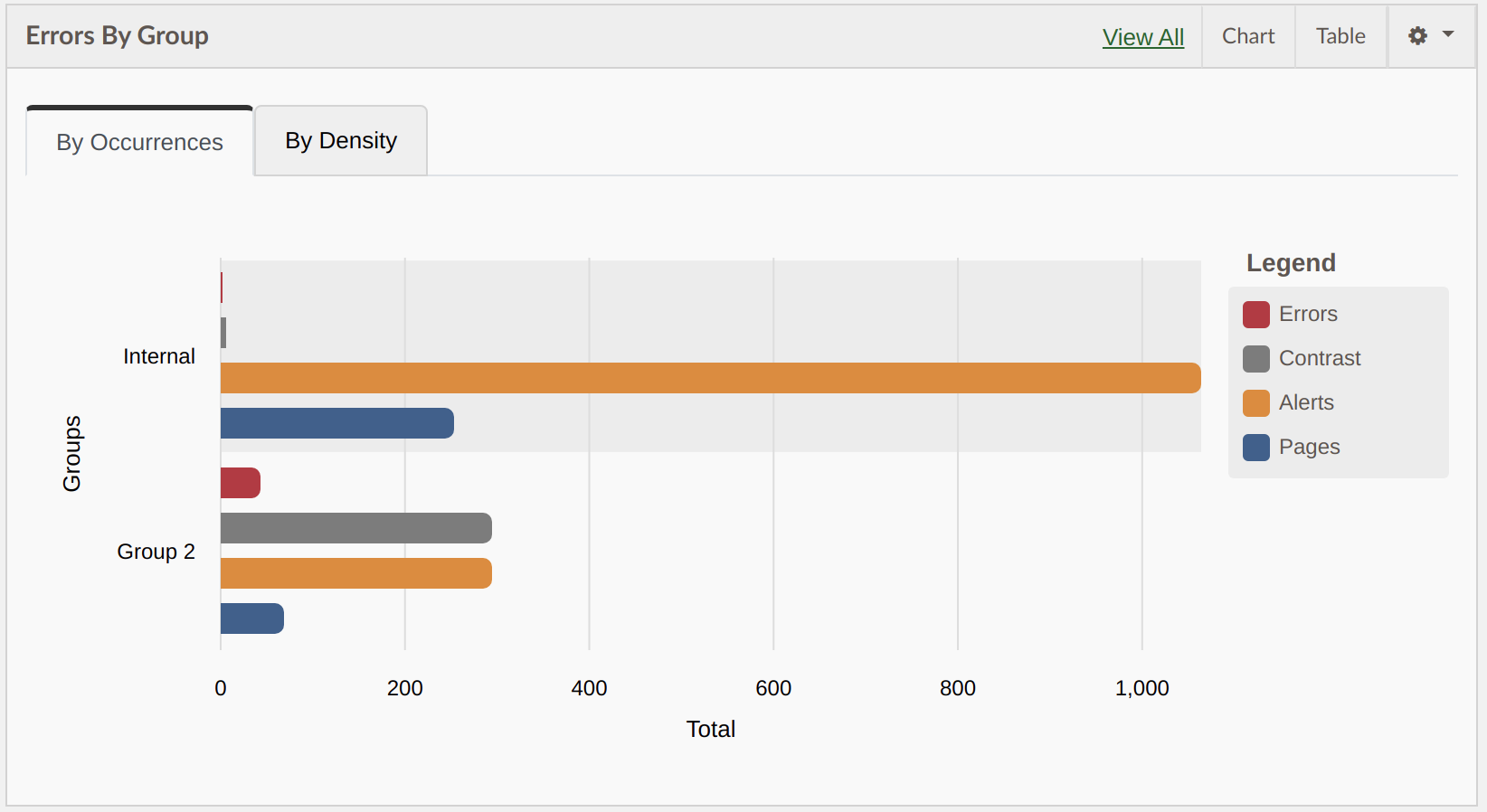
In addition a new category of “Pages” was added to view pages in each group while comparing results. To turn this on activate the widget settings button at the top of the widget and turn on the pages option.
Errors over time dashboard widget update
The errors over time widget was updated to show the graph filters always at the top of the widget. Previously the graph filters were hidden in a settings button.
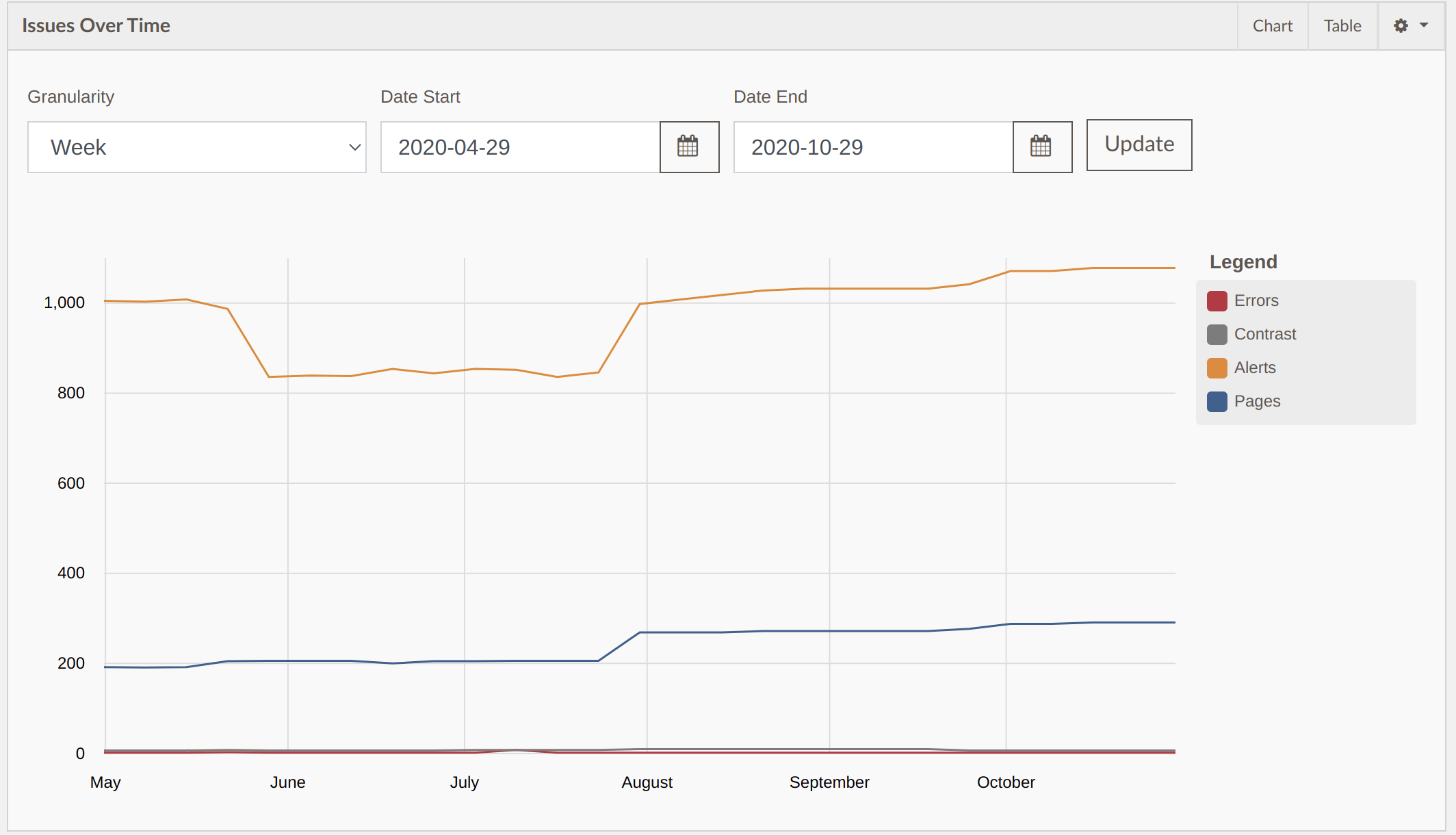
The Issues over graph can be filtered by Granularity, Start Date and End Date. By default it shows weekly granularity for the past 6 months.
Oct 14, 2020
Detecting YouTube videos – New Alert
This new Alert will detect if there is an embedded (within an iframe) YouTube video, or a link to a YouTube video present. This doesn’t test the captions of the video which need to be verified by a human.
This result makes it easier to find the scope of videos and where they are at on your website(s).
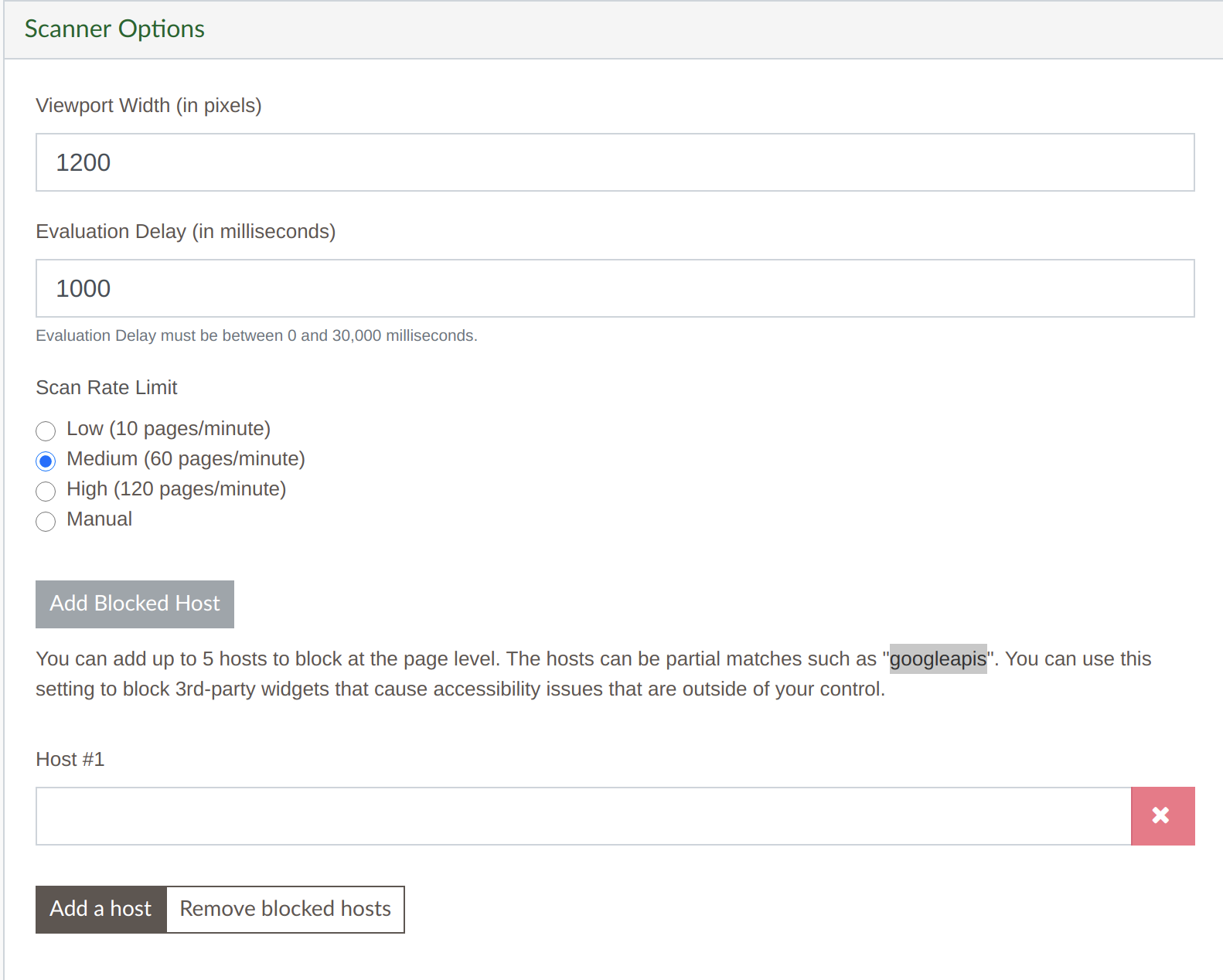
Block Host – New scan setting
The Blocked host Scanner Option allows you to block a specific host widget. For example you could block “maps.googleapis.com” to not load the Google Map content for your scan. Any external loaded script with the content of the blocked host won’t load for the scan.
Keep in mind that the accessibility of 3rd party widgets should still be considered and is important for your users – but sometimes it is helpful to remove those from your scan to focus on things you can more easily control.
At the bottom of the Scanner Options when editing a website activate the “Add Blocked Host” button to add a blocked host.
Over Time and Groups widget settings
On both the Over Time and Groups widgets you could adjust them to show Errors, Contrast Errors, or Alerts but it wouldn’t save your preference. With this update once you change your preference it will save to your user account until you change it again.
Oct 12, 2020 – Sitemap Import
We updated our crawling process to first check for a sitemap.xml file before crawling. If there is a sitemap it will import from the sitemap, if not it will crawl like a traditional crawl.
For websites that dynamically update their sitemap this is a great option to very quickly import every page and keep the pages up to date as the website is updated. A sitemap import is much faster than a traditional crawl and can adds thousands of pages in seconds.
This is a new setting found in a websites Crawler Options that is on by default and can be turned on/off per website. The setting is called, “Use Sitemap”.
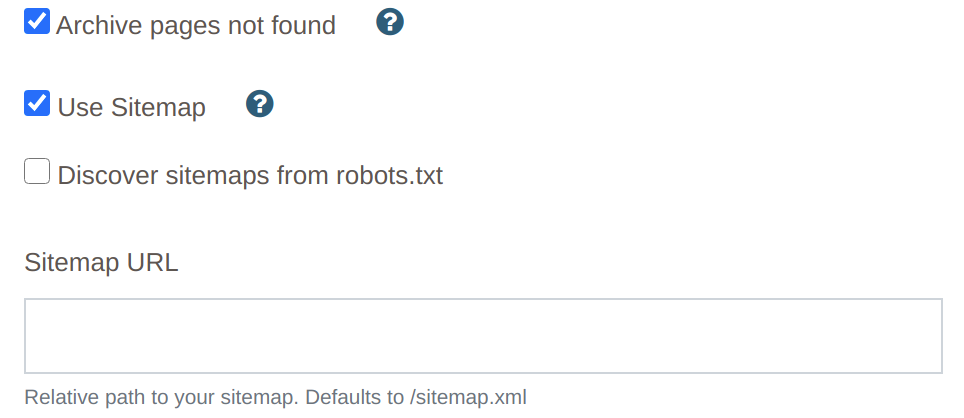
In addition if the sitemap is located in a different location this can be overridden with the “Sitemap URL” setting or you can list sitemaps in the websites robots.txt file and turn on the “Discover sitemaps from robots.txt” setting.
When importing pages from a sitemap the Max Pages and filters settings still apply and function the same as a traditional crawl.
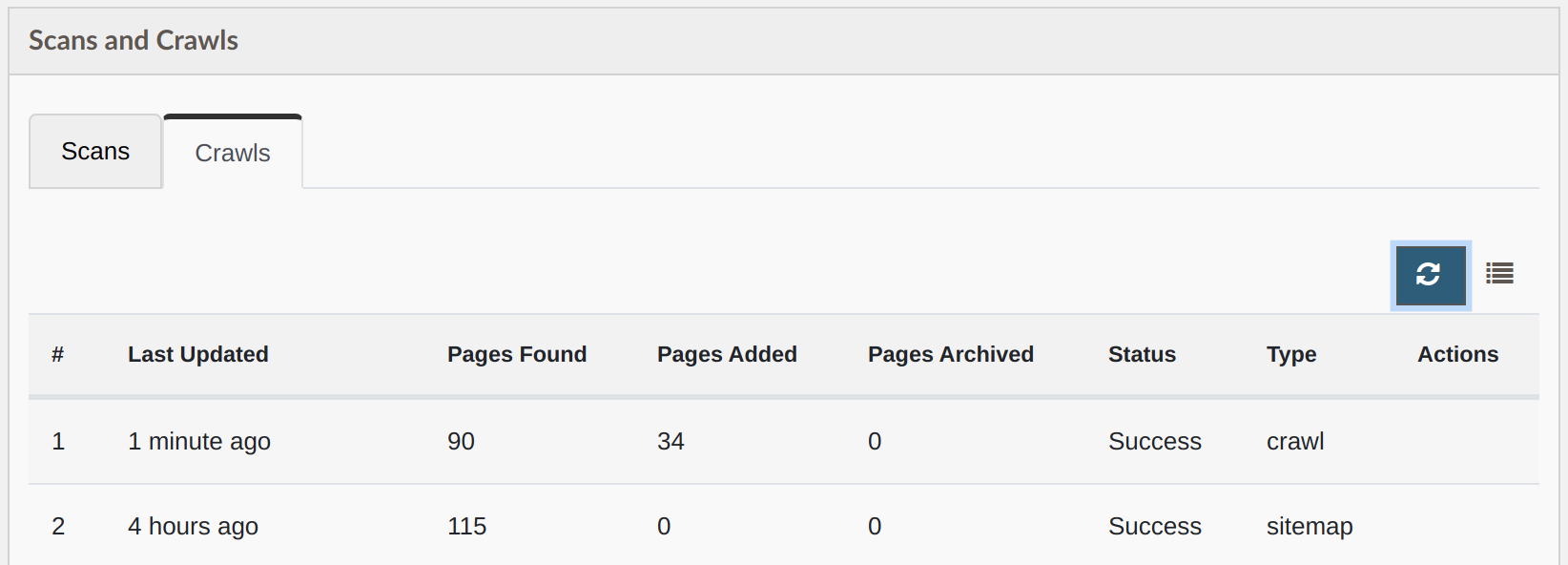
The Crawls tab has a new column indicating if the crawl was a sitemap import or a traditional crawl.
Archive pages not found setting
An additional setting has also been added to the Crawler Options called, “Archive pages not found”. This is off by default. When turned on either a traditional crawl or sitemap import will automatically archive any pages that aren’t found. Remember archived pages won’t change past scan data but aren’t scanned on future scans. If a future crawl/sitemap finds these pages again they are reactivated for future scans.
One note for this feature is to make sure your Max pages setting is higher than what is found or there might be some variability between crawls with pages being archived that still exist in the sitemap/are linked to.